Advent of Code 2021: Day 8

This blog post is eighth in the Advent of Code 2021 series and shows a JavaScript-based solution to the problem described in Day 8. The challenge was about decoding four-digit numbers represented using a seven-segment display. The difficulty in solving this problem increased compared to the previous days and I struggled a bit to find the solution in part two. However, this was my favourite challenge so far.
All solutions are in this GitHub repository.
Understanding the Problem
The problem is about decoding digits represented using a seven-segment display. Each segment has a name from a to g. By default, if we name the segments in order, the digits from 0 to 9 are represented by the segments abcefg, cf, acdeg, acdfg, bcdf, abdfg, abdefg, acf, abcdefg and abcdfg .
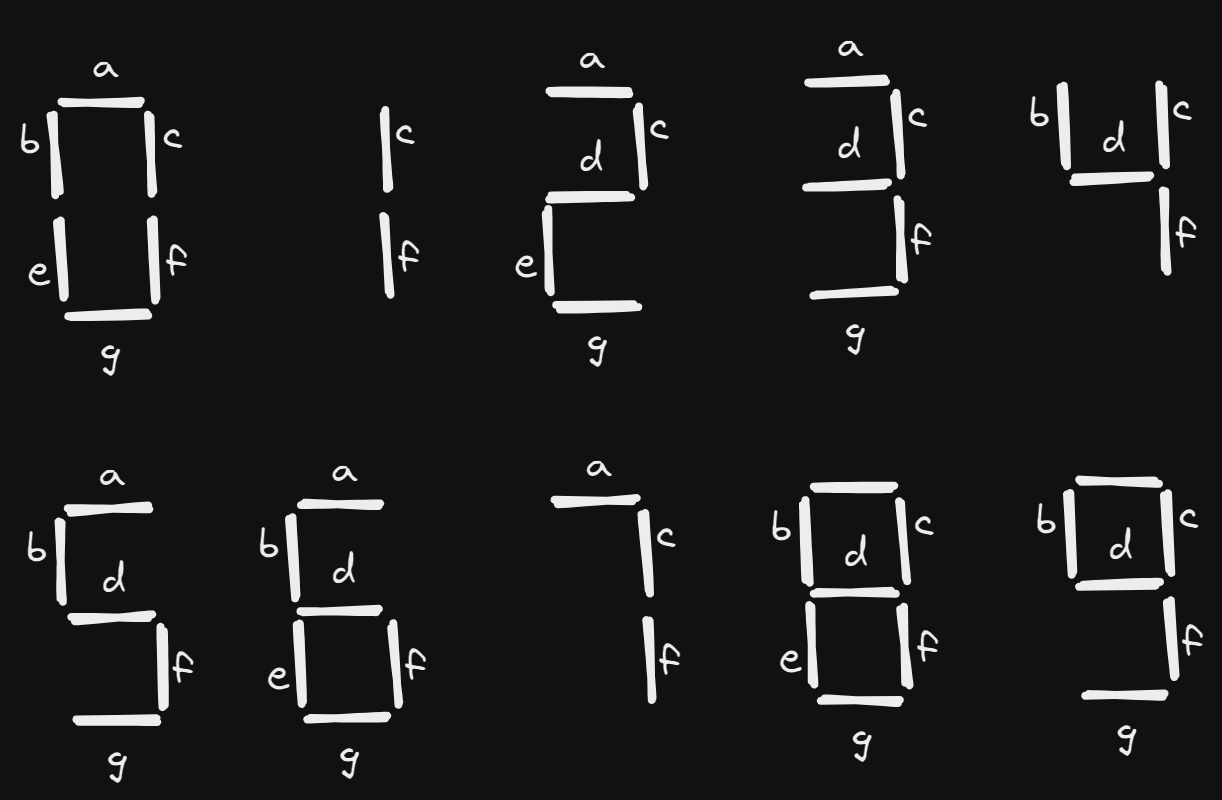
The problem is we don't know which letter corresponds to which segment. We must deduct it from a set of ten unique segment patterns representing digits from 0 to 9 given in random order. For example, given the pattern
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab
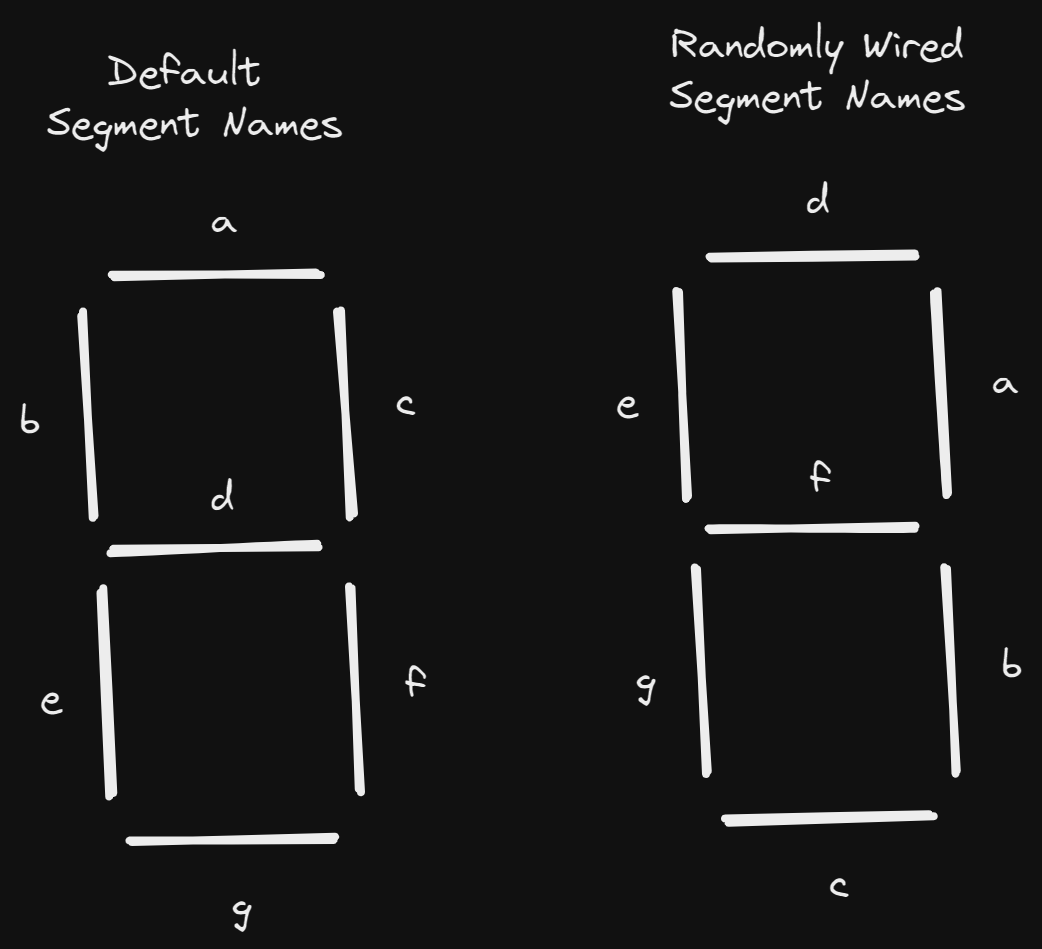
we must find a way to deduce the name of each segment. The segment mapping from the example is illustrated below.
The pattern from the example represents the following digits:
acedgfb: 8 cdfbe: 5 gcdfa: 2 fbcad: 3 dab: 7 cefabd: 9 cdfgeb: 6 eafb: 4 cagedb: 0 ab: 1
Understanding the Input
We are given multiple lines, each containing ten unique signal patterns, a delimiter and four output values. For example,
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab | cdfeb fcadb cdfeb cdbaf
Solving Part One
The goal is to count the number of four-digit output values representing either 1, 4, 7 and 8. The problem description hints that these digits have a unique number of segments. Indeed only 1 has two segments, only 4 has four segments, only 7 has three segments and only 8 has seven segments.
To solve part one we must:
- read the output values
- check if any output value has a unique length
- sum all output values with unique length
Read the output values
Since we only need the output value for part one, we can extract them from each line using the delimiter |.
const lines = data.split('\n')
const outputValues = lines.map((line) => line.split(' | ')[1])
Then to extract each digit into an array we can use the space as separator.
const digits = outputValue.split(" ")
Check if any output value has a unique length
Since 1, 4, 7, 8 are represented using 2, 4, 3, 7 segments respectively, we can check whether the length of the digit is one of those numbers. The includes function is useful for performing this check.
[2, 4, 3, 7].includes(digit.length)
Count all output values with unique length
We can use the reduce function to count output values respecting the condition previously defined.
digits.reduce((digitCount, digit) => {
if ([2, 4, 3, 7].includes(digit.length)) {
return digitCount + 1
}
return digitCount
}, 0)
Then, we can use the reduce function again to sum digits from all lines.
return outputValues.reduce((digitCount, outputValue) => {
const digits = outputValue.split(" ")
return digitCount + digits.reduce((count, digit) => {
if([2, 4, 3, 7].includes(digit.length)) {
return count + 1
}
return count
},0)
}, 0)
The final solution for part one is in my GitHub repository.
Solving Part Two
The second part of the problem was the tricky one. The goal of the second part was to decode all output values, from a four-digit number and sum all four-digit numbers.
I used a top-down approach where I wrote higher-level functions first and, thus defined the overall structure of the program, then defined the lower-level functions and went into detail. Here is how I broke down the problem:
- sum all output numbers
- decode output number
- find segment mapping
- reveal corresponding digits using segment map
- find output value based on revealed digits
The trickiest part was finding the segment mapping, in other words, identifying the name of each segment. The strategy was:
- calculating segment occurrences in all ten unique patterns
- identifying the segments with unique occurrences
- identifying digits with unique segment length
- use a process of elimination
Sum all output numbers
We can outline the solution as follows. We define the getOutput function afterwards.
const solve = (data) => {
const lines = data.split('\n')
return lines.reduce((sum, line) => sum + getOutput(line), 0)
}
Decode output number
We can further outline the solution:
const getOutput = (line) => {
const [segmentPatternsString, outputValuesString] = line.split(' | ')
const segmentMap = findSegmentNamesMap(segmentPatternsString)
const correspondingSevenSegmentDisplay = getSevenSegmentDisplay(segmentMap)
return getOutputDigits(outputValuesString, correspondingSevenSegmentDisplay)
}
Let's look at an example line. Given the line
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab | cdfeb fcadb cdfeb cdbaf
the segmentPatternsString is
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab
and outputValuesString is
cdfeb fcadb cdfeb cdbaf
The findSegmentNamesMap function returns the following mapping:
{
a: 'd',
b: 'e',
c: 'a',
d: 'f',
e: 'g',
f: 'b',
g: 'c',
}
The getSevenSegmentDisplay function maps each digit based on the default seven segment display.
So, the default seven-segment display
[ 'abcefg', 'cf', 'acdeg', 'acdfg', 'bcdf', 'abdfg', 'abdefg', 'acf', 'abcdefg', 'abcdfg']
becomes the following based on the segment names map
['abcdeg', 'ab', 'acdfg', 'abcdf', 'abef', 'bcdef', 'bcdefg', 'abd', 'abcdefg', 'abcdef']
Notice the letters are sorted alphabetically. This makes identifying the output digits easier.
The getOutputDigits maps the outputValuesString to 5353.
Find segment mapping
We can start by initializing the segment name map:
const findSegmentNamesMap = (segmentPatternsString) => {
const segmentMap = { a: '', b: '', c: '', d: '', e: '', f: '', g: '' }
return segmentMap
}
Identifying the segments with unique occurrences
Using the default segment names we have the digits from 0 to 9 represented as:
const sevenSegmentDisplay = [ 'abcefg', 'cf', 'acdeg', 'acdfg', 'bcdf', 'abdfg', 'abdefg', 'acf', 'abcdefg', 'abcdfg']
and each letter occurs as follows
const abcdefgOccurence = { a: 8, b: 6, c: 8, d: 7, e: 4, f: 9, g: 7 }
Thus, the b, e and f segments occur a unique number of times. We can use this information to determine the segment name mapping for these values.
const findSegmentNamesMap = (segmentPatternsString) => {
const segmentMap = { a: '', b: '', c: '', d: '', e: '', f: '', g: '' }
const letterOccurence = calculateLetterOccurence(segmentPatternsString)
segmentMap.b = findLetter(letterOccurence, abcdefgOccurence.b)
segmentMap.e = findLetter(letterOccurence, abcdefgOccurence.e)
segmentMap.f = findLetter(letterOccurence, abcdefgOccurence.f)
return segmentMap
}
Identifying segments based on digits with unique segment length
Part one hinted at using the length of digits. We can deduce a, c and d.
To find the segment corresponding to a, we can identify numbers 1 and 7 in the segmentPatternsString. We are looking for the letter not present in 1. For example, given ab and abd we can determine that d is the name corresponding to segment a.
const findA = (segmentPatternsString) => {
const one = findDigitBySignalsLength(segmentPatternsString, 2)
const seven = findDigitBySignalsLength(segmentPatternsString, 3)
let a = seven
one.split('').forEach((letter) => {
a = a.replace(letter, '')
})
return a
}
To find the segment corresponding to c, we can identify the number 1 in the segmentPatternsString and eliminate the previously found segment corresponding to f. For example, given ab and the previously found b corresponding to f, we can deduce that a is the name corresponding to c.
const findC = (segmentPatternsString, letterF) => {
const one = segmentPatternsString
.split(' ')
.find((digit) => digit.length === 2)
return one.replace(letterF, '')
}
To find the segment corresponding to d, we can identify the number4 in the segmentPatternsString and eliminate the previously found segment corresponding to b, c and f. For example, given eafb, and the previously found e corresponding to b, a corresponding to c and b corresponding to f, we can deduce that f is the name corresponding to d.
const findD = (segmentPatternsString, signalMap) => {
const four = findDigitBySignalsLength(segmentPatternsString, 4)
return four
.replace(signalMap.b, '')
.replace(signalMap.c, '')
.replace(signalMap.f, '')
}
Use a process of elimination
After mapping a, b, c, d, e and f, we can determine the segment corresponding to g by process of elimination.
const findG = (signalMap) => {
let allLetters = 'abcdefg'
Object.keys(signalMap).forEach(
(key) => (allLetters = allLetters.replace(signalMap[key], ''))
)
return allLetters
}
The final solution for part two is in my GitHub repository.
Conclusion
Day 8 was really challenging and entailed decoding numbers by identifying unique occurrences, segment lengths and by process of elimination.




